在2025年全球AI大模型竞速的背景下,中美两国的技术路线和商业策略呈现出显著差异。这场竞赛不仅是技术实力的较量,更是一场围绕成本、普惠性和生态构建的深层博弈。从定价策略到技术开源,从算力基础设施到市场渗透,两国的选择折射出截然不同的产业逻辑。

基础模型价格对比
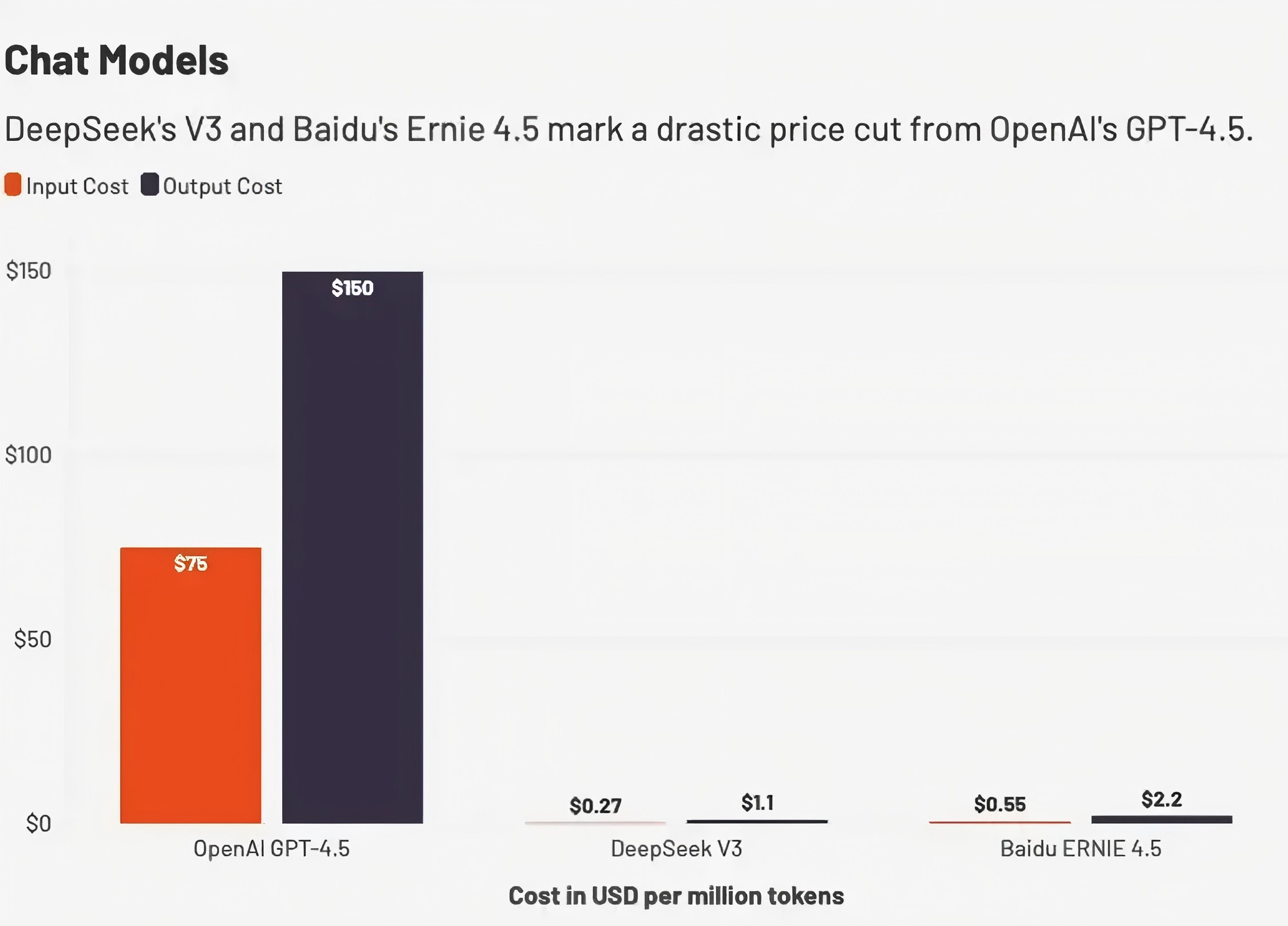
价格鸿沟:成本优势的颠覆性突破
中国AI大模型的核心竞争力,首先体现在价格维度上的颠覆性优势。以百度文心大模型4.5为例,其API调用成本仅为GPT-4.5的1%——输入价格低至0.004元/千tokens,输出价格0.016元/千tokens。这种差距并非孤立现象:DeepSeek的推理模型R1定价甚至低于OpenAI同类产品的2%,而其训练成本仅为国际头部模型的1/30。这种价格优势的背后,是中国企业对算法效率的极致优化。例如,百度通过自研昆仑芯片和四层技术栈(芯片-框架-模型-应用),将推理成本压缩至一年前的1%,而DeepSeek开发的FlashMLA解码内核,在英伟达H800 GPU上实现了580TFLOPS的计算性能突破,使算力利用率达到国际领先水平。
技术路径:开源生态与闭源垄断的分野
在技术普惠的赛道上,中国企业选择了更具开放性的策略。百度宣布文心大模型4.5全面开源,并将深度搜索功能免费开放,这种“技术民主化”的尝试与OpenAI的闭源模式形成鲜明对比。DeepSeek更是在2025年初掀起开源浪潮,不仅开放模型权重,还释放了FlashMLA、DeepEP等核心代码库,使得中小开发者能以极低成本构建高性能模型。反观美国,尽管xAI的Grok 3宣布免费开放,但其技术门槛仍受限于十万卡集群的算力基础,本质仍是资本密集型路线的延续。这种差异导致的结果是:中国AI应用的渗透速度远超预期——DeepSeek R1发布7天内用户破亿,而同期美国同类产品的用户增长主要依赖企业级市场。
市场逻辑:普惠化与高溢价的角力
价格战的本质是市场主导权的争夺。中美两国在AI大模型领域的定价策略差异,折射出技术演进路径与市场生态的深层次分野。
美国厂商依托先发技术优势构建起"科研溢价"体系,OpenAI的GPT-4 Turbo通过参数规模和专利壁垒形成技术定价权,这种模式本质上是在全球知识价值链顶端征收"技术税",Anthropic推出的博士级AI服务将定制化知识图谱构建与私有化部署深度结合,25万美元的年起价不仅包含300轮强化学习迭代,更通过15毫秒延迟保障构建起服务壁垒,其合规性认证带来的40%溢价凸显出对全球商业规则的把控能力。
中国厂商则采取"场景穿透"策略破局,通过激进降价甚至免费策略,快速占领中小企业和个人开发者市场。dsspseek的免费API并非简单让利,而是通过智能路由技术将70%请求导流至参数量缩减83%的裁剪模型,在保障用户体验的同时控制边际成本。这种看似激进的定价背后是数据反哺机制的精密设计,某头部平台免费条款中隐含着38%训练语料的数据使用权,开发者调用行为本身就在持续强化模型竞争力。
在这场全球AI定价权争夺战中,美国试图通过技术复杂度构建知识税基,中国则以场景深度重构价值链条。
未来图景:成本革命与技术长跑的平衡
这场竞赛的终局尚未明朗,但趋势已现端倪。中国通过“算法优化+算力自主+开源生态”的三重路径,正在打破AI领域的“摩尔定律魔咒”——即性能提升必须伴随成本上升的固有规律。百度昆仑芯三代万卡集群的落地,以及DeepSeek在训练成本上实现的指数级下降,预示着技术普惠可能真正走向大众。而美国尽管在绝对技术实力上仍具优势(如GPT-4.5的多模态能力),但其依赖高融资支撑的商业模式正面临挑战:OpenAI单轮400亿美元的融资需求,本质上是将研发成本转嫁给终端用户,这种模式在价格敏感型市场中难以持续。
在这场跨越太平洋的AI竞速中,优惠已不仅仅是价格数字的对比,更是技术路线、产业生态和社会价值的综合博弈。当中国企业用开源代码和极致性价比撕开技术垄断的铁幕时,全球AI产业的权力结构正在悄然重构——这或许正是2025年最值得书写的技术民主化篇章。
相关推荐

京东相关负责人回应,目前公司高度重视包括具身智能、大模型在内的技术热点。未来将聚焦供应链场景,持续通过内部技术创新和外部投资等方式来构建技术创新生态。...

马斯克于当地时间周一宣布,Grok 付费订阅用户现可试用 AI 聊天机器人新版“虚拟伙伴”(Companions)功能,但也有部分免费用户称其亦可访问该功能。...

7 月 12 日,OpenAI 首席执行官山姆・奥尔特曼(Sam Altman)在 X 平台发布推文,表示为进一步测试模型安全,将推迟发布其首个开源 AI 模型。...

欧盟委员会昨日(7 月 10 日)发布公告,推出最终版《通用人工智能行为准则》(General-Purpose AI Code of Practice),帮助企业在开发 AI 过程中遵守相关监管标准。...



